
医疗科研数据跨机构安全共享与隐私计算方案
发布时间:2025-05-08 23:17 浏览次数:次 作者:admin
一、行业现状:数据共享的困境与机遇
医疗科研数据的价值早已被行业公认,但现实中的跨机构共享却举步维艰。根据《2023中国医疗数据应用白皮书》,我国医疗数据利用率仅为8.3%,远低于欧美国家的32%。这一矛盾背后,隐藏着三个亟待破解的核心问题:
1. 数据孤岛:散落的科研"金矿"
系统割裂:某省级医疗集团下属12家医院使用6种不同的HIS系统,数据互通需手动导出Excel表格耗时3个月。
标准缺失:同一患者的CT影像在A医院采用DICOM 3.0标准,到B医院却因版本差异导致三维重建失败。
典型案例:某罕见病研究项目因样本量不足陷入停滞,需联合30家医院的数据支持,但数据整合耗时超1年。
2. 隐私雷区:合规与效能的博弈
泄露代价:美国Anthem保险数据泄露事件赔付1.15亿美元,国内某基因公司因数据跨境传输违规被罚2000万元。
脱敏困局:某三甲医院对10万份病历进行传统脱敏后,关键字段(如发病时间、伴随症状)完整性损失60%。
3. 协作黑洞:看不见的成本吞噬
技术负债:某跨国药企为接入5家医院数据,投入300万元开发定制接口,但3年后系统升级导致接口失效。
信任危机:科研机构与医院因数据权属争议,导致价值5亿元的AI辅助诊断项目流产。
1. 联邦学习(FL):分布式建模的实践
核心逻辑:各参与方本地训练模型,仅交换加密参数更新。
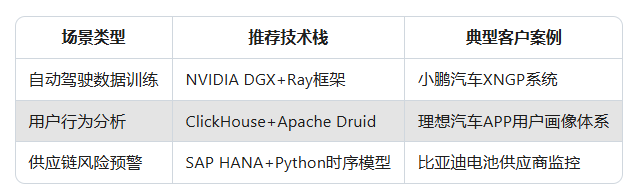
应用案例:上海瑞金医院联合基层医院构建糖尿病视网膜病变模型,样本量从5000例扩展到15万例,准确率提升至96%。
技术优势:
支持异构数据协同(如CT影像+电子病历)
内置差分隐私,单点数据泄露不影响全局模型
典型场景:
多中心基因组分析:20家医院联合计算基因突变频率,原始数据全程密态
药品不良反应监测:药企在TEE内分析医院脱敏数据,输出风险预警信号
标准化改造:采用FHIR标准统一数据结构,某区域影像平台对接效率提升70%。
流行病防控:省级疾控中心利用MPC技术统计跨区域感染数据,疫情预测准确率提升42%。
数据银行模式:医院将脱敏数据存入"数据保险箱",药企按次付费调用,单次分析费用300-5000元。
API市场建设:医疗机构发布标准化数据服务接口,第三方机构通过隐私计算网关调用。
误区1:过度追求技术先进性,忽略业务适配性
反面案例:某医院强行部署TEE方案,因硬件兼容性问题导致300万元投入闲置
误区2:低估数据治理复杂度
教训总结:某AI公司80%项目周期耗费在数据清洗对齐
能力扩展(6-12个月):接入电子病历、基因组等多模态数据
生态运营(12+个月):构建数据服务API市场,探索商业化模式
1. 智能数据治理引擎
场景化建模:预置200+医疗数据模型(如肿瘤标志物分析模型)
自动化映射:不同HIS系统字段映射效率提升90%
客户案例:某三甲医院3周完成10年历史数据治理,数据可用率从35%提升至92%
混合计算架构:本地部署敏感数据处理模块,云端运行轻量化分析
区块链存证:完整记录数据使用轨迹,满足FDA电子数据审计要求
方案亮点:
开箱即用的《医疗数据合规指南》模板库
支持千节点级联邦学习网络,时延<50ms
与阿里云TEE、微众银行FATE等生态深度集成
六、未来展望:数据驱动的医疗研究新范式
AI协同计算:GPT-4医疗版实现多模态数据(文本+影像+基因组)联合推理
实时科研网络:突发传染病数据24小时内完成全球安全共享
自主进化系统:隐私计算模型自动优化参数,准确率月均提升1.2%
如果您有物料编码相关的问题,欢迎咨询新易物料编码
医疗科研数据的价值早已被行业公认,但现实中的跨机构共享却举步维艰。根据《2023中国医疗数据应用白皮书》,我国医疗数据利用率仅为8.3%,远低于欧美国家的32%。这一矛盾背后,隐藏着三个亟待破解的核心问题:
1. 数据孤岛:散落的科研"金矿"
系统割裂:某省级医疗集团下属12家医院使用6种不同的HIS系统,数据互通需手动导出Excel表格耗时3个月。
标准缺失:同一患者的CT影像在A医院采用DICOM 3.0标准,到B医院却因版本差异导致三维重建失败。
典型案例:某罕见病研究项目因样本量不足陷入停滞,需联合30家医院的数据支持,但数据整合耗时超1年。
2. 隐私雷区:合规与效能的博弈
泄露代价:美国Anthem保险数据泄露事件赔付1.15亿美元,国内某基因公司因数据跨境传输违规被罚2000万元。
脱敏困局:某三甲医院对10万份病历进行传统脱敏后,关键字段(如发病时间、伴随症状)完整性损失60%。
3. 协作黑洞:看不见的成本吞噬
技术负债:某跨国药企为接入5家医院数据,投入300万元开发定制接口,但3年后系统升级导致接口失效。
信任危机:科研机构与医院因数据权属争议,导致价值5亿元的AI辅助诊断项目流产。
二、技术破局:隐私计算的三重武器
隐私计算技术正在重塑医疗数据共享规则,通过"数据不动计算动"的模式破解传统难题。以下是主流技术路线的深度解析:1. 联邦学习(FL):分布式建模的实践
核心逻辑:各参与方本地训练模型,仅交换加密参数更新。
应用案例:上海瑞金医院联合基层医院构建糖尿病视网膜病变模型,样本量从5000例扩展到15万例,准确率提升至96%。
技术优势:
支持异构数据协同(如CT影像+电子病历)
内置差分隐私,单点数据泄露不影响全局模型
2. 可信执行环境(TEE):硬件级安全堡垒
实现路径:基于Intel SGX/AMD SEV构建隔离环境,数据仅在加密状态下离开本地。典型场景:
多中心基因组分析:20家医院联合计算基因突变频率,原始数据全程密态
药品不良反应监测:药企在TEE内分析医院脱敏数据,输出风险预警信号
3. 技术选型对照指南
三、落地方法论:从试点到生态的四步走
1. 数据治理筑基标准化改造:采用FHIR标准统一数据结构,某区域影像平台对接效率提升70%。
2. 场景化突破
药物研发:某抗癌药三期临床试验通过FL技术整合8国数据,入组速度提升50%。流行病防控:省级疾控中心利用MPC技术统计跨区域感染数据,疫情预测准确率提升42%。
3. 协作机制创新
智能合约确权:某多中心研究项目通过区块链记录数据贡献,按权重分配专利收益。数据银行模式:医院将脱敏数据存入"数据保险箱",药企按次付费调用,单次分析费用300-5000元。
4. 生态体系构建
混合云架构:本地存储原始数据,云端部署隐私计算节点,某跨国项目节省硬件投入80%。API市场建设:医疗机构发布标准化数据服务接口,第三方机构通过隐私计算网关调用。
四、企业选型指南:避开五大常见陷阱
1. 技术选型四大误区误区1:过度追求技术先进性,忽略业务适配性
反面案例:某医院强行部署TEE方案,因硬件兼容性问题导致300万元投入闲置
误区2:低估数据治理复杂度
教训总结:某AI公司80%项目周期耗费在数据清洗对齐
2. 能力评估清单
3. 分阶段实施路线图
单点验证(3-6个月):选择影像辅助诊断等高价值场景能力扩展(6-12个月):接入电子病历、基因组等多模态数据
生态运营(12+个月):构建数据服务API市场,探索商业化模式
五、方案:医疗数据共享的"高速公路"
1. 智能数据治理引擎
场景化建模:预置200+医疗数据模型(如肿瘤标志物分析模型)
自动化映射:不同HIS系统字段映射效率提升90%
客户案例:某三甲医院3周完成10年历史数据治理,数据可用率从35%提升至92%
2. 隐私计算工厂
零门槛操作:拖拽式配置联邦学习流程,支持可视化效果追踪混合计算架构:本地部署敏感数据处理模块,云端运行轻量化分析
3. 生态连接器
标准化API网关:提供药品研发、临床研究等6大类数据服务接口区块链存证:完整记录数据使用轨迹,满足FDA电子数据审计要求
方案亮点:
开箱即用的《医疗数据合规指南》模板库
支持千节点级联邦学习网络,时延<50ms
与阿里云TEE、微众银行FATE等生态深度集成
六、未来展望:数据驱动的医疗研究新范式
AI协同计算:GPT-4医疗版实现多模态数据(文本+影像+基因组)联合推理
实时科研网络:突发传染病数据24小时内完成全球安全共享
自主进化系统:隐私计算模型自动优化参数,准确率月均提升1.2%
结语:让数据安全流动,让科研无界协同
医疗数据共享不是简单的技术命题,而是需要技术工具、制度设计、商业模式的协同创新。选择兼具工程化能力与医疗洞察的平台,将帮助机构在保障安全的前提下,充分释放数据价值。当数据真正成为可安全流通的"生产要素"时,医疗科研的边界将被彻底打破。如果您有物料编码相关的问题,欢迎咨询新易物料编码
(部分内容来源网络,如有侵权请联系删除)
 上一篇
上一篇 








